Advertisement
There's something quite interesting happening in the world of AI, and this time, it's from a name most associated with data warehousing. Snowflake just introduced a text-embedding model, and they're calling it the world’s best when it comes to Retrieval-Augmented Generation (RAG). That's not just bold talk. The early numbers and what this means for businesses working with large volumes of unstructured text show there's real weight behind the claim.
If you've been reading RAG breakthroughs even vaguely, you know this is where generation and search converge. It's a basic premise: rather than pre-filling your chatbot or AI system with all the information it needs to respond, you let it go retrieve what's necessary from a database of knowledge — and only afterward give the response. That fetch part? That's where embedding models excel. And it's the one Snowflake just refined.
Let's start with what this model isn't. It's not a general-purpose language model like GPT or Claude. It's not there to write your essays or make predictions. Its job is more specific: take a chunk of text and turn it into a dense vector of numbers so that it can be compared with other chunks of text in a way that's meaningful.
Here's what Snowflake has done differently. First, they've trained this model directly on RAG tasks. That's not always the case. Many embedding models are trained on things like sentence similarity or classification tasks and then repurposed for RAG. Snowflake skipped that route. They fine-tuned the model from the ground up, with retrieval as the end goal. The result? Significantly better recall at top-k — especially top-1 and top-5 — which is what matters most when your system needs to find the right document, not just something vaguely related.
According to Snowflake, this model outperforms everything else currently available. That includes leading open models like E5 and GTE and even proprietary options that many teams still consider best-in-class. On the Massive Text Embedding Benchmark (MTEB), Snowflake's model ranks #1 for retrieval — a first for any enterprise-focused model of its kind.
If you’re building anything with RAG — from internal search tools to support chatbots or research assistants — embedding quality is your bottleneck. You can fine-tune your retriever and tweak your ranker all day, but if the vector representation of your data is fuzzy or inconsistent, the whole system struggles.
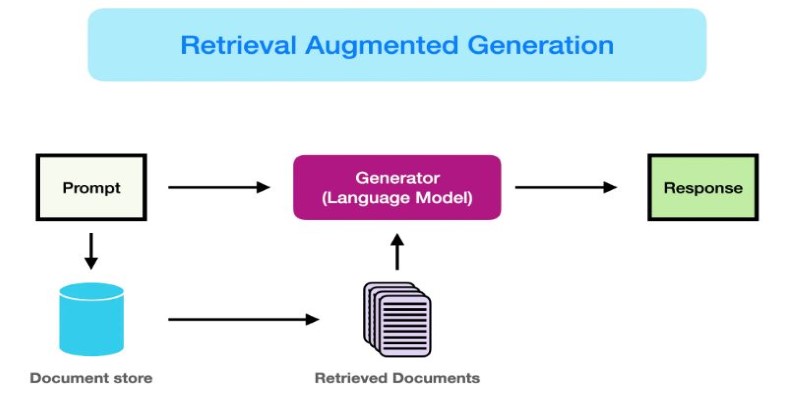
Snowflake’s new model changes what you can expect at this step. With higher precision in retrieval, your generator has better input to work with. That alone means faster answers, fewer hallucations, and much less hand-holding during implementation. And this improvement doesn’t just shave a few milliseconds or edge out a tiny margin. It simplifies system design.
Better embeddings mean less post-processing. You're not relying on extra filters or re-ranking to make up for a weak vector match. In small teams, where computing and time are tight, that's a big shift.
Snowflake didn't just make the model available; they've integrated it directly into Cortex, their enterprise-grade AI offering. So, if your data already lives in Snowflake — whether structured, semi-structured, or unstructured — you can generate and use embeddings in place without setting up a separate vector database or retriever. The goal here is frictionless adoption.
In terms of scale, Snowflake claims the model performs well across a range of dataset sizes. Whether you're indexing 10,000 documents or 10 million, you don’t need a different tool or retraining cycle. That flexibility matters because enterprise use cases tend to grow — fast. A small internal knowledge base often becomes a full-stack document search system once adoption spreads.
And because this model is integrated with Cortex, teams can use familiar SQL workflows to run embedding jobs, manage indexes, and hook them into RAG pipelines. For those already operating inside the Snowflake ecosystem, this removes a whole layer of engineering overhead.
To bring this into your workflow, start by preparing your documents. These can include PDFs, HTML, plain text, or database entries. Break them into clear, manageable chunks. RAG systems work best with short, coherent sections rather than long blocks of text.

Next, generate embeddings using Snowflake Cortex. If you use SQL, the process is familiar. Cortex provides user-defined functions (UDFs) to embed each chunk and store the vectors directly in your Snowflake instance.
After embedding, create a vector index. Snowflake supports this natively, so there’s no need for external tools. You can search your data within the same environment.
When a user asks a question, convert it into an embedding using the same model. Search the index for the closest matches and pass the top results to your language model — whether it's from OpenAI, Anthropic, Mistral, or another source. This retrieved context improves the relevance and accuracy of the response.
Finally, monitor results and make adjustments as needed. If irrelevant documents show up too often, tweak chunk sizes, indexing strategy, or ranking settings. Better retrieval reduces the workload on the language model and improves output quality.
Snowflake’s move into embedding models might seem like a detour from its data roots, but it makes perfect sense if you look at where enterprise AI is going. As more organizations adopt RAG to make sense of their data, the need for solid, high-performance embeddings becomes non-negotiable. And instead of just supporting third-party models, Snowflake built their own — optimized for the exact thing customers are trying to do. It’s not just a performance win. It’s about reducing the gap between storage and intelligence.
When your data, compute, and AI tools sit in one place, systems become easier to build, cheaper to run, and more consistent in output. With this release, Snowflake isn’t just enabling RAG — it’s redefining the standard for enterprise-grade AI infrastructure.
Advertisement

Learn simple steps to prepare and organize your data for AI development success.

Learn how to make your custom Python objects behave like built-in types with operator overloading. Master the essential methods for +, -, ==, and more in Python

Discover how generative AI for the artist has evolved, transforming creativity, expression, and the entire artistic journey

MIT is leading a focused initiative to integrate AI and emerging technologies into manufacturing, prioritizing real-world impact for manufacturers of all sizes
Curious how Tableau actually uses AI to make data work better for you? This article breaks down practical features that save time, spot trends, and simplify decisions—without overcomplicating anything

Work doesn’t have to be a grind. Discover how CrewAI and Groq help you design agentic workflows that think, adapt, and deliver—freeing you up for bigger wins

Learn how the SQL SELECT statement works, why it's so useful, and how to run smarter queries to grab exactly the data you need without the extra clutter

Learn how ThoughtSpot's AI agent, Spotter, revolutionizes conversational BI for smarter and more accessible business insights

Discover Reka Core, the AI model that processes text, images, audio, and video in one system. Learn how it integrates multiple formats to provide smart, contextual understanding in real-time

Need to round numbers to two decimals in Python but not sure which method to use? Here's a clear look at 9 different ways, each suited for different needs

Think picking the right algorithm is enough? Learn how tuning hyperparameters unlocks faster, stronger, and more accurate machine learning models

Improve machine learning models with prompt programming. Enhance accuracy, streamline tasks, and solve complex problems across domains using structured guidance and automation.